eDocs ホーム > BEA AquaLogic Data Services Platform 3.0/3.2 ドキュメント > ALDSP 3.2 の新機能ドキュメント
| [作成者] |
Mike Carey |
| バージョン |
ALDSP 3.2 |
XQuery Scripting Extension (XQSE) 言語は、ALDSP 3 で新しく導入した XQuery 拡張です。XQSE によって、ALDSP の以前のリリースでは XQuery を終了せずに、カスタム Java コードを記述することなしにはできなかった多くのことが容易にできるようになります。このガイドの目的は、XQSE を使用することで ALDSP で利用できるようになった機能について説明することです。これは、より形式的 XQSE 言語参照のためのガイドです。
|
このガイドでは、XQuery (または Java) に記述する代わりに、指定されたデータ サービス オペレーションを記述するために XQSE をいつ、どのような理由で使用するべきかについて説明します。 従って、このガイドは一連の「一般的な XQSE」ツアーとしてまとめられています。このガイドには、XQSE を使用しなければならないユースケースが含まれ、各ユースケースに対応するために XQSE とそのさまざまな機能がどのようにまたなぜ役立つかについて簡単にまとめています。
ユーザの利便性とエンターテイメントのために、ここで説明したすべてのデータが、インポート可能な ALDSP 3.0 データ スペース プロジェクトとしても利用できます。次に進む前に、そのプロジェクトをインポートする必要があります。XQSE-How-To プロジェクトの基底のリレーショナル データ ソースがすべて ALDSP 3.0 にパッケージされており、インポート後は、XQSE を学習するために必要なデータがすべて揃っているので、独自の XQSE を作成することができます。
次へ進む前に、この言語の素晴らしさその名前にお気づきのことと思います。それに気づいていない場合、XQSE は「excuse」で、XQSE は「excuses」と発音します。 上司から、重要なデータ サービスの用意ができているかどうかをたずねられたら、「まだ用意できていません。でもとても最適な XQSE ならあります。」と答えることができます。素晴らしい言語ではないでしょうか。
XQSE-How-To プロジェクトは、社員と部門の古いサンプルのあるリレーショナル データ ベースによるシナリオに基づきます。これには、3 つのテーブルが含まれます。1 番目の仮想のデータ ソースからの EMP および DEPT の関連テーブル 2 つ (Pointbase JDBC データ ソース dspSamplesDataSource サンプルから抽出) および 2 番目の仮想のデータ ソース (Pointbase JDBC データ ソース dspSamplesDataSource1 から) の 3 番目のテーブル EMP2 です。
|
プロジェクトを検討する場合、次の場所からダウンロードすることができます。 http://edocs.bea.com/aldsp/docs30/code/XQSE-How-To-artifacts-32.zip JAR ファイルをローカル ディレクトリに保存し、ALDSP が開いている状態でプロジェクトをインポートします。
|
EMP/DEPT テーブルには、社員の上司、部門および収入に対する情報が含まれます。経営階層は、データ依存の再帰または反復を必要とする ALDSP ユースケースによって XQSE がどのように役立つかを示すステージを設定します。EMP は、XQSE が更新時にビジネス ルールのチェックおよび実行に対してどのように使用されるかを示すためにも使用されます。EMP2 テーブルには、EMP と同じ多くの情報が含まれますが、情報を表すフォーマットが異なり、仮想的に別の地理的な場所に存在するため、変換および複製に関するユースケースでどのように XQSE が役立つかについてを示すステージを設定します。これにより、XQSE を使用して、大量更新と増分更新に対するカスタム更新関連のロジックを表す方法および XQSE での例外の処理についても示します。
参照として、3 つのサンプル テーブルを作成および入力するために使用する DDL 文を以下に示します。テーブルが 3 つとも 1 つの Pointbase データベースに依存します。それらは、複数の異なる JDBC データ ソース (ALDSP では、各 JDBC データ ソースは、別々の関連データ ソースとして処理されるので、分散されたデータベース環境をシミュレートするために) を通じて ALDSP に表示されます。
CREATE SCHEMA EMP_DEMO; CREATE TABLE EMP_DEMO.EMP ( EID VARCHAR(8) NOT NULL, MID VARCHAR(8), NAME VARCHAR(32) NOT NULL, SALARY DECIMAL(10,2), DEPTNO INTEGER ); ALTER TABLE EMP_DEMO.EMP ADD CONSTRAINT EMP_PK PRIMARY KEY (EID); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO ) VALUES( 'EMP1', 'Charlie Chairman', 1250000.00, 10 ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP2', 'Dave Divisionhead', 275000.00, 10, 'EMP1' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP3', 'Suzy Supervisor', 250000.00, 10, 'EMP1' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP4', 'Denise Departmenthead', 180000.00, 20, 'EMP2' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP5', 'Alfred Architect', 175000.00, 20, 'EMP2' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP6', 'Larry Leafnode', 95000.00, 20, 'EMP3' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP7', 'Emily Engineer', 125000.00, 30, 'EMP3' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP8', 'Gregory Groupleader', 145000.00, 30, 'EMP4' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP9', 'Peter Peon', 79000.00, 30, 'EMP8' ); CREATE TABLE EMP_DEMO.EMP2 ( EmpId VARCHAR(8) NOT NULL, FirstName VARCHAR(32), LastName VARCHAR(32), MgrName VARCHAR(32), Dept INTEGER ); ALTER TABLE EMP_DEMO.EMP2 ADD CONSTRAINT EMP2_PK PRIMARY KEY (EmpId); CREATE TABLE EMP_DEMO.DEPT ( DNO INTEGER NOT NULL, DNAME VARCHAR(32) NOT NULL ); ALTER TABLE EMP_DEMO.DEPT ADD CONSTRAINT DEPT_PK PRIMARY KEY (DNO); INSERT INTO EMP_DEMO.DEPT ( DNO, DNAME ) VALUES( 10, 'Administration' ); INSERT INTO EMP_DEMO.DEPT ( DNO, DNAME ) VALUES( 20, 'Engineering' ); INSERT INTO EMP_DEMO.DEPT ( DNO, DNAME ) VALUES( 30, 'Testing' ); ALTER TABLE EMP_DEMO.EMP ADD CONSTRAINT DEPT_FK FOREIGN KEY (DEPTNO) REFERENCES EMP_DEMO.DEPT;
Data Services Studio プロジェクト エクスプローラを使用して、XQSE-How-To プロジェクトを参照すると、3 つのテーブルともリレーショナル タイプの物理データ サービスとして、サンプル プロジェクトにインポートされていることが分かります。以下に示すモデル ダイアグラム (XQSE how-to サンプル プロジェクト内の RelationalSources.md) は、これらの 3 つのリレーショナルベースの物理データ サービスの ALDSP での概要を示しています。

以下の図は、XQSE How-To プロジェクトの論理データ サービスと物理データ サービスおよびその間の関連付けの概要を示します。まず、Employee という論理データ サービスを作成します。これは、EMP (および DEPT の可能性もありますが、このガイドでは、DEPT のコンテンツは実際には使用しません) からの従業員データのクリーンアップ ビューを提供します。このデータ サービスは、XQSE 関数が利用できない場合のいくつかの重要な読み取り専用のユースケースの説明に使用します。Employee データ サービスは、データの変更要求があれば、XQSE を使用してビジネス ルールを強化する方法も説明します。
次に、EmployeeBackup というライブラリ データ サービスを作成します。このデータ サービスは、「lightweight ETL」ユースケースで XQSE がどう役に立つかについて説明します。このデータ サービスの主な機能として、このデータ サービスを呼び出すと、Employee からのデータを EMP2 に一括複製することができます。
最後に、ReplicatedEmployee というエンティティ データ サービスを作成します。ReplicatedEmployee は、XQSE を使用して、更新処理のカスタマイズ方法を示します。このデータ サービスは、XQSE を使用して、Employee および EMP2 間の情報を同期化します。

XQSE が更新のカスタマイズに重要なだけではなく、読み取り専用ユースケースの特定のクラスにも使用します。そのために、ALDSP 3.0 は、XQSE 関数だけではなくプロシージャもサポートします。そのため、最適な XQSE を開発方法を学習する必要があります。この部分の学習に関する例が、XQSE How-To サンプル プロジェクトの論理データ サービス Employee.ds を中心とします。
Employee データ サービスのデザイン ビューには、以下のものがあります。
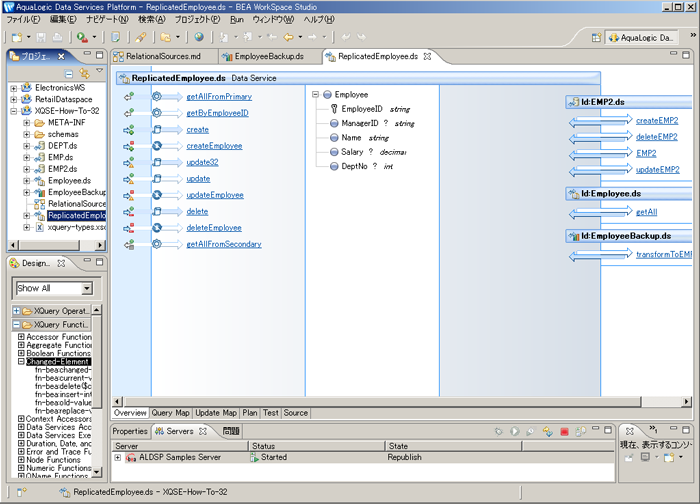
Employee データ サービスは、単純な論理データ サービスであり、後続の使用のために見掛けを良くするように論理 EMP データを少し変更します。Employee データ サービスの getAll() 関数のクエリ マップ ビューを検討すると、そのプライマリ 読み取り関数が非常に簡単であることが分かります。
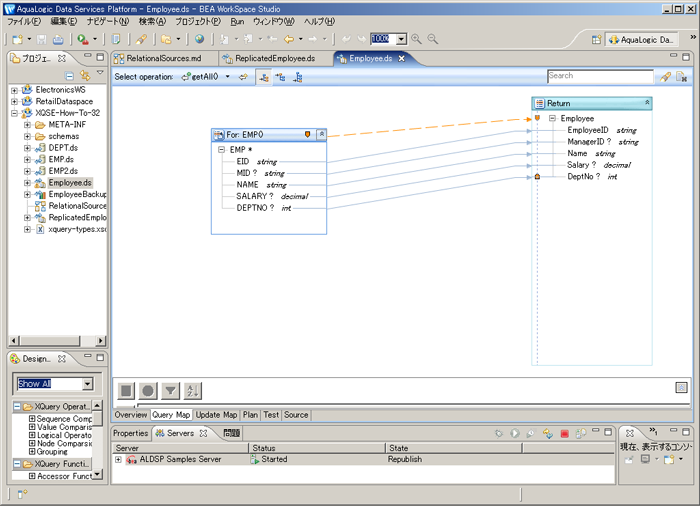
関心のあるさまざまな XQSE 関数の詳細について説明する前に、使用する Employee データに関する感覚をつかむ必要があります。サンプル プロジェクトのコピーを使用して getAll() 関数を実行すると、次を返します。
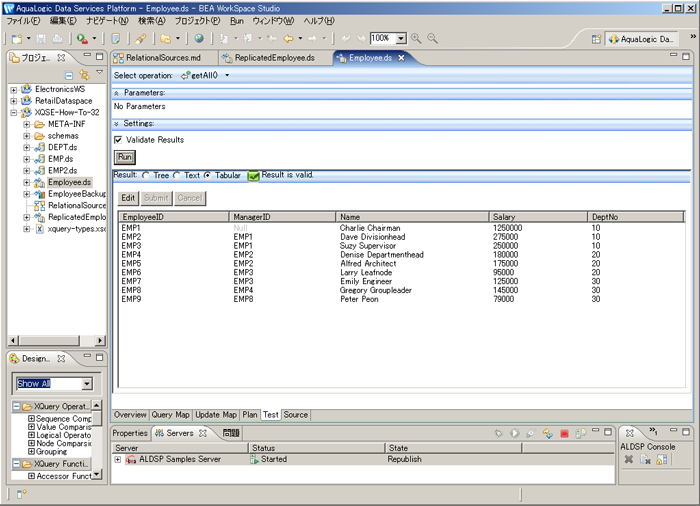
ご覧のとおり、結果がテーブル形式であり、小企業の各従業員の従業員の ID、管理者 ID、従業員名、給与額および部門番号が含まれます。CEO は、Charlie Chairman という名前の従業員で、彼はマネージャーを持たないのでトップ レベルの従業員と見なすことができます。管理者 ID を使用して、誰が誰の部下として働くかについての情報がデータベースにエンコードされます。管理者 Suzy および部長 Dave の二人の管理者 ID が EMP1 (Charlie の従業員の ID) であるために Charlie の部下として働き、Larry Leafnode および Emily Engineer が Suzy の部下として働きます。全従業員、例えば、従業員 ID および以前に、直接または間接に Charlie の部下として働いた全従業員を含め、完全なレポート ツリーを描く場合、次の図になります。

ご覧とおりに、このデータは、再帰的なデータであり、ALDSP では、再帰的な XQuery 関数が利用不可能なため、XQuery を使用して処理するのは大変です。ただし、XQSE では、再帰的な XQuery 関数が利用可能です。すぐに理解できるように、このデータを処理するのは、反復または再帰のいずれかを使用した XQSE の最適なユースケースです。XQSE を使用して、上記のようにレポート ツリーを作成することができます。
基本的に、XQuery で再帰を要求するユースケースであれば、XQSE に対する良いユースケースを見つけることになります。使用するユースケースでは、末尾再帰のみ必要であれば、XQSE の反復および再帰のいずれか (より自然なもの、つまり習慣的な思考によって) を使用して、それを試みることができます。ごユースケースでは、報告ツリーの例のように完全な再帰が必要であれば、XQSE の再帰を使用して問題を対応することができます。これから、XQSE How-To サンプル プロジェクトのこのようなユースケースの例を見て見ましょう。
XQSE 関数およびプロシージャでは、XQSE と XQuery の両方からのコンストラクトを使用することができます。検討しようとしているユースケースについては、従業員 ID または管理者 ID のいずれかに基づいて、Employee インスタンスを取得する関数を持つと便利です。以下の XQuery ソールは、ここで XQSE ユースケースのために必要な Employee DS getAll() 関数の XQuery 定義および この関数を使用して、getByEmployeeID と getByManagerID の 2 つの XQuery ヘルパー関数の作成方法を示します。それらの関数の機能と機能方法は、みてすぐに分かります。それらの 3 つの関数はすべて、Employee のゼロ以上のインスタンスを返すので、Employee データ サービスの読み込み処理として分類されます。
(::pragma function <f:function kind="read" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getAll() as element(empl:Employee)* { for $EMP in emp:EMP() return <empl:Employee> <EmployeeID>{fn:data($EMP/EID)}</EmployeeID> <ManagerID?>{fn:data($EMP/MID)}</ManagerID> <Name>{fn:data($EMP/NAME)}</Name> <Salary?>{fn:data($EMP/SALARY)}</Salary> <DeptNo?>{fn:data($EMP/DEPTNO)}</DeptNo> </empl:Employee> }; (::pragma function <f:function kind="read" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getByEmployeeID($id as xs:string?) as element(empl:Employee)* { for $emp in tns:getAll() where $id eq $emp/EmployeeID return $emp }; (::pragma function <f:function kind="read" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getByManagerID($id as xs:string?) as element(empl:Employee)* { for $emp in tns:getAll() where $id eq $emp/ManagerID return $emp };
XQSE How-To サンプル プロジェクトの最初の例は、Employee.ds 内の distanceFromTop() の関数です。ユースケースは単純です。従業員の従業員 ID を知っていて、その従業員が企業の階層の位置、つまり、トップ レベルからどの位置になっているかを知りたいとします。Charlie Chairman の distanceFromTop は 0 で、会長です。Suzy Supervisor はトップ レベルから 1 つの位置に離れているから、distanceFromTop は 1 です。彼女は、Charlie の部下として働いています。Emily Engineer は、Suzy の部下として働いているので、distanceFromTop は 2 です。コンセプトを理解しましたか。しかし、これを簡単に計算することができるでしょうか。ALDSP の XQuery を使用しては計算できませんが、XQSE を使用することで可能になります。Employee.ds の distanceFromTop() 関数のソース ビューを開くと、XQSE の最初の honest-to-goodness 関数を表示することができます。
(::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare xqse function tns:distanceFromTop($id as xs:string?) as xs:integer? { declare $mgrCnt as xs:integer := 0; declare $curEmp as element(empl:Employee)?:= tns:getByEmployeeID($id); declare $mgrId as xs:string?:= fn:data($curEmp/ManagerID); if (fn:empty($curEmp)) then return value (); while (fn:not(fn:empty($mgrId))) { set $mgrCnt := $mgrCnt + 1; set $curEmp := tns:getByEmployeeID($mgrId); set $mgrId := fn:data($curEmp/ManagerID); }; return value ($mgrCnt); };
関数のシグネチャは、XQuery 関数と似ていますが、「xqse」の修飾子が異なります。修飾子は、この関数の本文には、XQuery だけではなく、XQSE コードも含まれていることを ALDSP に伝えます。また、これは関数であり、副作用がないなどより良く動作することについても伝えます。
関数の本文には、まず、mgrCnt、curEmp および mgrId の 3 つの変数を宣言します。mgrCnt の初期化値は 0 で、トップから離れている位置を追跡します。curEmp の初期化値は ID を持つ従業員で、考慮する現在の従業員を追跡します。mgrId は、現在の従業員の管理者 ID を保持します。
それらの変数を定義して、初期化された後、この関数は、if 文を使用して、指定した ID の従業員が存在しない場合、空のシーケンス (XQuery および XQSE 等価の null) を即座に返します。その後、関数は、while 文を使用して、従業員の現在の位置から企業のトップ レベルまで移動します。while ループは、管理者 ID 有り・管理者 ID なしによって示すとおりに、現在の従業員がトップの従業員にならない限り実行されます。
各反復では、新しい従業員を古い従業員の管理者として設定すると、離れた距離に 1 を追加し、新しい従業員から管理者 ID を抽出します。ループを終了すると、トップの位置に達成し、離れた距離が mgrCnt に登録されます。つまり、mgrCnt の値が返されます。XQSE を使用して、拡張した XQuery コードで、以前に ALDSP では、難しく解決不可能に見えた問題を解決できるようになります。成功!この時点で、今までの処理を理解したことを確認する必要があります。ひと休みしてから、必要に応じて、もう一度コードを学習し、Data Services Studio のテスト ビューに移動します。Peter Peon の distanceFromTop は何ですか。回答は妥当なものでしょうか。今まで見てきた処理で試してみる場合、XQSE コードを手動で実行し、なぜ、Peter の回答は 4 になるかを見ます。
直前に見た、distanceFromTop() 関数では、反復ソリューションを使用して、従業員の階層内の従業員の位置を数えました。これは、多くの人が取る自然なアプローチです。もう一つのソリューションとしては、再帰を使用することがあります。従業員が会長 (例えば、従業員に管理者がない) の場合、distanceFromTop の値がゼロで、単に従業員の管理者の distanceFromTop です。その以外の場合、1 を追加した値になります。以下に示しており、Employee DS に提供した、XQSE の関数、distanceFromTop2() は、次のように問題を解決します。これは、末尾再帰を使用した XQSE 関数の例です。distanceFromTop2() および直前に説明した XQSE 関数、distanceFromTop() の間の類似点に注意してください。主な相違点は、distanceFromTop2() 関数はループ処理を行いません。その代わりに、関数自体を管理者 ID で呼び出して、現在の従業員の管理者のロジックを「繰り返します」。
(::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare xqse function tns:distanceFromTop2($id as xs:string?) as xs:integer? { declare $curEmp as element(empl:Employee)?:= tns:getByEmployeeID($id); declare $mgrId as xs:string?:= fn:data($curEmp/ManagerID); if (fn:empty($curEmp)) then return value (); if (fn:not(fn:empty($mgrId))) then { return value 1 + tns:distanceFromTop2($mgrId); } else { return value 0; }; };
次の XQSE 関数のユースケースは、一番目のユースケースと同じです。ただし、XQuery および XQSE のデータ処理能力を向上させる方法を示します。このユースケースの前提条件は同じです。従業員 ID はあります。けれども今度は、従業員の管理階層に誰がいるかという詳細な情報を知りたいとします。(従業員が、好ましくないことをした場合、それを好転させる方法を知りたいでしょう! ![]() )。このためには、従業員の情報、従業員の管理者の情報の順番で、会長の情報を取るまで、従業員の管理者チェーンを定義します。
)。このためには、従業員の情報、従業員の管理者の情報の順番で、会長の情報を取るまで、従業員の管理者チェーンを定義します。
次に示す employee DS にある managementChain() 関数の XQSE コードは、この順序を計算します。構造的に distanceFromTop() 関数とほとんど同じです。主な相違点は、この関数は、ゼロからカウントする代わりに、結果として起こったシーケンス (empChain) を現在の従業員になるように初期化し、管理者チェーンが会長まで達成するまでにループして、新しい従業員を最後に更新してい行きます。
(::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare xqse function tns:managementChain($id as xs:string?) as element(empl:Employee)* { declare $curEmp as element(empl:Employee)?:= tns:getByEmployeeID($id); declare $empChain as element(empl:Employee)* := $curEmp; declare $mgrId as xs:string?:= fn:data($curEmp/ManagerID); while (fn:not(fn:empty($mgrId))) { set $curEmp := tns:getByEmployeeID($mgrId); set $empChain := ($empChain, $curEmp); set $mgrId := fn:data($curEmp/ManagerID); } return value ($empChain); };
distanceFromTop() を理解していると、managementChain() 関数の動作するロジックについてもすぐに理解できます。この XQSE 関数をテスト ビューで実行してみてください。Peter Peon については、以下を参照してください。

もう 1 つのユースケース「recursive grand finale」をみて XQSE 関数についての説明を終了しましょう。たとえば、指定した従業員のレポート ツリ-、XQSE 関数の紹介で前に説明した種類のツリーを計算するとします。
Employee データ サービス内の XQSE の関数 reportingTree() は、以下とまったく同じではありません。これが短くて単純であることに注意してください。XQSE では、わずかなコードで多くのことを実現できます。curEmp 変数は、現在の従業員を示し、reports (管理者 ID で従業員を表示する XQuery のヘルパー関数を使用して取得する) 変数は、現在の従業員を直接レポートする従業員のリストを示します。
現在の従業員のレポート ツリーはどのように見えるでしょうか。簡単です。ツリーには、従業員 ID、従業員名および彼らがそれぞれレポートする従業員のレポート ツリーを含む必要があります。XQSE のソリューションは、この問題を再帰を使用して解決します。レポートのレポート ツリーのシーケンスを小さい XQuery「for $rep in $reports return tns:reportingTree($rep/EmployeeID)」を使用して計算します。この例では、XQuery および XQSE は、問題を自然に解決するためにどのように組み合わせるかについて例示しています。XQSE 関数は単に関数で、ALDSP XQuery のクエリがどの場所からも XQSE の関数を呼び出すことができるので、XQuery から XQSE 関数を呼び出すことが有効です。(Factoid: このユースケースは、XQSE How-To プロジェクトの一部になっていました。これは、このユースケース開発時に、だれかがこのユースケースをそのまま ldblazers に追加したからです。)
(::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare xqse function tns:reportingTree($id as xs:string?) as element(EmpTree)? { declare $curEmp as element(empl:Employee)?:= tns:getByEmployeeID($id); declare $reports as element(empl:Employee)* := tns:getByManagerID($id); declare $result as element(EmpTree)? := <EmpTree?> <EmpID?>{fn:data($curEmp/EmployeeID)}</EmpID> <EmpName?>{fn:data($curEmp/Name)}</EmpName> <Reports?>{ for $rep in $reports return tns:reportingTree($rep/EmployeeID) }</Reports> </EmpTree>; return value ($result); };
では、ここから開始します。XQSE を使用して、XQSE 関数を書くことで、以前に解決されることができなかったユースケースをどのように計算するかについて説明しました。また、XQSE 言語の変更可能な変数、割り当て文、if 文および while 文などさまざまな機能が公開されています。
それでは、更新のカスタムカが必要となる XQSE の「bread & butter」というユースケースを見てみましょう。ALDSP 3.0 の以前のバージョンでは、ほとんどのカスタム更新ユースケースには、Java プログラミングが必要でした。現在は、このようなユースケースの大数のクラスを ALDSP の新しい更新マップ エディタを使用して処理することができます。処理できない場合はどうでしょう。処理できない、ユースケースを XQSE を使用して処理します。ALDSP 3.0 では、XQSE を使用して、独自のカスタムの作成、挿入および更新プロシージャや副作用のあるライブラリ プロシージャを書くことで、独自の更新ロジックを書くことができます。データ サービスのコンシューマが後でこれを呼び出すことができます。更新プロシージャは、システムで自動生成された更新ロジックの代わりに使用するか、またはそれと一緒 (コントロールを使用したり、ロジックを追加したり、システム自体のルーチンをご本文内から呼び出す方法で) に使用します。
XQSE How-To のこの節では、更新カスタム化を呼び出す代表的な例を 2 つ説明します。最初の例は、XQSE を使用して、副作用のある SQL ストアド プロシージャとよく似ている、独自のプロシージャを書く方法について示します。その後、アプリケーションに通知させて、新しいプロシージャを呼び出します。次の例では、ALDSP の Java または Web サービス Mediator API を使用して、クライアント アプリケーションによって、SDO ベースの更新時に行われることを強化するために独自のロジックのシステムの自動更新に機械的に投入する方法を示します。これらの両方の例は、今まで処理した Employee データ サービスに基づきます。このために、次へ進む前に、Employee データ サービスの更新マップ ビューを見ましょう。
Employee データ サービスの更新マップ ビューには、以下のものがあります。
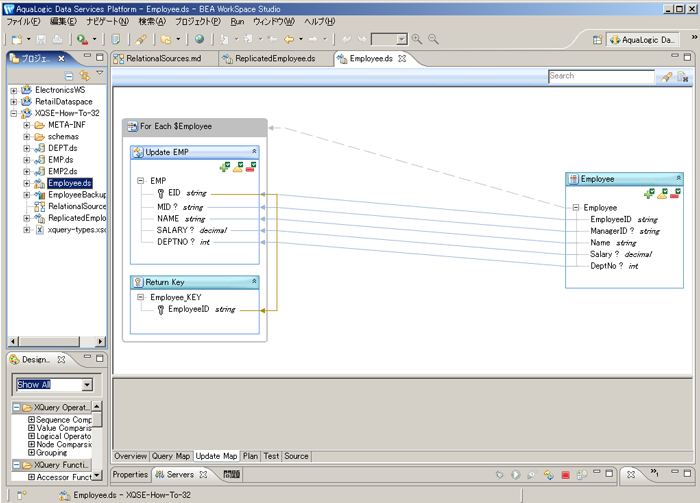
この更新マップは、ALDSP 3.0 における通常の方法で生成されました。このガイドでは、ALDSP 3 の更新マップ機能に関する知識を前提としています。知識がない場合は、『データ サービス開発者ガイド』の更新マップの管理を参照してください。
ALDSP では、Employee データ サービスの更新の完全なセットの生成は問題なくできます。プライマリ 読み取り関数 (getAll() 関数と指定される) は、名前の再マッピングをします。こらは、ALDSP の更新系統分析によって、簡単にリバース エンジニアリングすることができます。その結果、Employee データ サービスの create()、update() および delete() プロシージャが問題なく自動的に生成されました。
更新マップ ビューは、データの挿入、変更または削除した Employee インスタンス (ビューの右部に表示する) から基底のリレーショナルベースの EMP データ サービス (左部に表示する) への移動方法および create() 呼び出しによって返されたキーの元 (EMP の EID から) を示します。
次のソース コードの抜粋は、システム提供の更新プロシージャの結果のオペレーション シグネチャおよびプラグマを示します。最初に、insert() および delete() プロシージャがパブリックであり、update() プロシージャが Employee データ サービス (以下に説明する) のプライベート操作になるように変更されています。同様にすぐに説明できる理由で、update() がプライマリでなくても (isPrimary = "false")、insert() および delete() プロシージャがプライマリ (つまり、SDO 更新を処理する自動化の指定したハンドラ) としてフラグされます。すべての 3 つの関数は、外部関数であり、ALDSP の自動更新機能によって実装されます。(つまり、その実装型は、「updateTemplate」です。)
(::pragma function <f:function kind="update" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:update($arg as changed-element(empl:Employee)*) as empty() external; (::pragma function <f:function kind="create" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:create($arg as element(empl:Employee)*) as element(empl:Employee_KEY)* external; (::pragma function <f:function kind="delete" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:delete($arg as element(empl:Employee)*) as empty() external;
今までのところは問題ありませんでした。それでは、何をカスタマイズする必要があるでしょう。クライアント アプリケーションの開発者が Employee インスタンスをまず ALDSP から検索せず削除できることとします。代わりに、彼らは、従業員 ID に基づいて「blind delete」オペレーションを実行するようにしようとします。(つまり、ある時に、Employee インスタンスにあるデータに関係なく、企業から指定した ID の従業員 をすぐ削除する必要があります。)この要件に満たすには、XQSE にライブラリ プロシージャを書きます。このプロシージャを使用すると、指定した ID の従業員を検索し、システム生成した削除オペレーションを呼び出します。このためには、次の 2 行のプロシージャを使用します。
(::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:deleteByEmployeeID($id as xs:string?) as empty() { declare $emp as element(empl:Employee)?:= tns:getByEmployeeID($id); tns:delete($emp); };
更新のカスタム化のもう一つの理由は、更新がアプリケーションのビジネス ルールに違反しない必要があるからです。たとえば、データを表示している小規模企業では、給与を大幅に増加または減少してはいけないようなルールがあれば、従業員の給与を 一度に 10% を超えて変更すると、企業のルールに違反したことになります。XQSE のいくつかの行で、このようなビジネス ルールの反映がいかに簡単に実行できるかを見てみましょう。
まず、更新がこの 10% ビジネス ルールに違反するかどうかを理解する必要があります。XQuery に短いブール関数を書くことで必要なチェックができます。10% ルールについて、Employee データ サービスでプライベート関数 invalidSalary() を使用してこのチェックを行います。この関数には、引数として、変更する従業員および変更済みの要素 (従業員) のインスタンスを渡します。これには、更新する従業員インスタンスの現在の値と古い値にアクセスするために、ALDSP より提供されるノード関数の fn-bea:current-value() および fn-bea:old-value() を使用します。古い給与と新しい給与を比較して、10% のルールに違反したかどうかを検出し、要求した変更が、有効の場合、true を返します。
(::pragma function <f:function kind="library" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:invalidSalaryChange($emp as changed-element(empl:Employee)) as xs:boolean { let $newSalary := fn:data(fn-bea:current-value($emp)/Salary) let $oldSalary := fn:data(fn-bea:old-value($emp)/Salary) return (100.0 * fn:abs($newSalary - $oldSalary) div $oldSalary) gt 10.0 };
ビジネス ルールをエンコードする XQuery 関数を提供したので、XQSE を使用してルールを実行することが簡単になります。次の XQSE 関数、updateChecked() は、シグネチャがシステム生成した更新関数と同じです。変更する Employee インスタンスのシーケンスを取得しますが、要求した更新が有効である場合のみ、実行します。
そのためには、XQSE の iterate 文を使用し、入力する従業員インスタンスに対して反復します。インスタンスのいすれかでは、給与額が大きすぎる場合、fn:error() を使用して例外を送出します。変更がすべて有効な場合、変更済みの従業員インスタンスに対してシステム提供した update() 関数を呼び出します。updateChecked() は、プライマリおよびパブリックとしてマークされているので、アプリケーションでは、この updateChecked() 操作が表示でき、更新時に呼び出されます。
(::pragma function <f:function kind="update" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:updateChecked($changedEmps as changed-element(empl:Employee)*) { iterate $sourceEmp over $changedEmps { if (tns:invalidSalaryChange($sourceEmp)) then fn:error(xs:QName("INVALID_SALARY_CHANGE"), ": Salary change exceeds the limit."); }; tns:update($changedEmps); };
明確になったでしょうか。これは、XQSE の重要な (および共有) 使用パターンです。XQSE を使用して、ALDSP により自動的に生成された更新処理ロジックをオーバーライドするには、システムのルーチンを非プライマリにし、代わりに、XQSE を使用して、独自の新しい作成、更新や削除オペレーションを記述します。XQSE では、すべての操作を実行できます。また、前に説明したとおりに、必要となる特別の処理を行って、残りの更新処理を後で処理するために、システムのルーチンに戻ります。レイヤー化された設計から見ると、ほとんどの場合、この処理をする必要があります。システムにジョブを終了させてから誰かがその前のレイヤーにおける「ジョブの終了」を意味する変更を行った場合、今まで行った処理は有効なままです。システムの処理でなく、自分で処理する場合、変更があった後で独自のロジックを調整する場合があります。
もう一つの特定の種類の更新は、「完全にカプセル化された更新」としてカテゴライズされます。リレーショナルな世界では、アプリケーション開発者が SQL を使用して更新することを禁止することはよくあることです。代わりに、データベースを更新する時に、一連の承認されたストアド プロシージャを使用するというような制限があります。XQSE を使用してサーバ側のプロシージャを書くことができます。同じようながものを SOA の世界でも行うことができます。
単純な例として、次の XQSE プロシージャは、従業員 ID および旧新部門 ID の値を取ります。これらの値を入力すると、古い部門の従業員が検索され、新しい部門に再び割り当てられます。再び割り当てるには、fn-bea:replace-value() 関数を使用し、従業員の部門番号を変更します。この関数は、ALDSP 3.2 で新たに追加された 3 つの「mutator」関数の 1 つです。(fn-bea:delete() および fn-bea:insert-into() を含む)。mutator 関数は、入力値として、変更済みの要素を取り、次に行う変更を含む修正したコピーを返します。この場合は、修正するのは、古く部門番号を必要な新しい値に置き換えることです。最後に、この例では、transfer プロシージャは、転送に成功した場合、true を返します。そうでなければ、false を返します。
(::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:transfer($id as xs:string, $fromDeptNo as xs:int, $toDeptNo as xs:int) as xs:boolean { declare $xferEmp as element(empl:Employee)?:= tns:getByEmployeeID($id)[DeptNo eq $fromDeptNo]; if (fn:exists($xferEmp)) then { declare $chgdEmp as changed-element(empl:Employee)?:= fn-bea:changed-element($xferEmp); set $chgdEmp := fn-bea:replace-value($chgdEmp, "DeptNo", $toDeptNo); tns:update($chgdEmp); return value fn:true(); } else { return value fn:false(); }; };
次へ進む前に、Data Services Studio 内の Employee.ds を試して見る必要があります。今まで説明した、さまざまなデータ サービス操作を行って見てください。1 つの読み込み関数を使用して、Peter Peon を含む従業員のセットを読み込みます。給与額を 2 倍増加した場合、何が起こるかを見ます。今年ではなかったけれど!
この時点で、XQSE のほとんどの実際の機能、そして一般的な使用について見てきました。この時点まで説明したのは、XQSE を使用して、複雑な手順のロジックが必要となる関数の書き方、プロシージャなど副作用操作の書き方およびシステムが提供した更新の置き換えまたは増加するカスタム更新ロジックの書き方です。ここで、独自の update を腕まくりして更新マップをなんとか記述することができるようになっています。もちろん、 XQSE が一番です。もちろん、 XQSE が一番です。実際にここにあるのです!お読みください。
データ サービスで時折に発生するユース ケースのクラスは、「lightweight ETL」です。ETL (または extract, transform, load) システムは、エンタープライズ ミドルウェア システムであり、データをオペレーション システムからデータ ウェアハウスに移動します。常に、データを 1 つのフォーマットから別のフォーマットに変換します。高性能の ETL システムは、非常に高速なデータ移動、平行度および確認・再起動性などの機能があります。
もちろん、有名な映画からの引用で言い換えれば、偉大な力は巨大な価格表とともにやってきます。そして ALDSP の顧客は 小さな ELT を持ち、それ以外の特別なソフトウェア パッケージの購入なしに済むことを望んでいます。ALDSP 3 では、XQSE を使用して、「lightweight ETL」のユース ケースを使用することができます。この節には、これについて説明します。XQSE How-To のサンプル プロジェクトでは、EmployeeBackup というライブラリ データ サービスがあります。これには、1 つの例が含まれます。EmployeeBackup.ds のデザイン ビューを開くと、この DS 上に 3 つの操作があることが分かります。
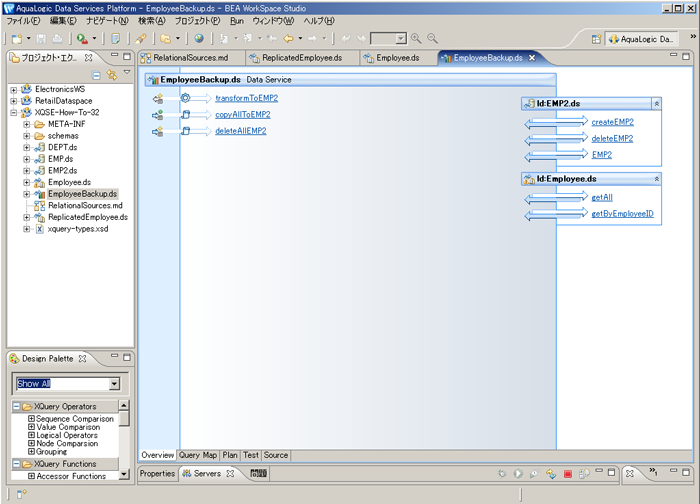
最初の操作は、別の XQuery ヘルパー関数です。また、XQuery は、XQSE の一部であり、実際のユースケースを解決する時によくこれらの両方を混同するのは、XQuery で可能な機能と XQSE で提供されたより高度な機能を必要とする場合です。
この場合には、XQuery ヘルパー関数 transformToEMP2() は、従業員のインスタンスを入力として取り、EMP2 のインスタンスとして再変形します。この関数は、「ETL」の「T」部分を行います。この関数は、その入力データを別の場所に使用する (たとえば、ロード) ために指定した形に変形します。この関数の XQuery ソース コードは、以下に示します。データの変形方法を見ます。この関数は、入力名をターゲットによって必要とする複数の部分に解析し、データベースを参照して、入力管理者 ID をターゲットによって必要な管理者名に変換します。すべてはとても単純で一連のエクスキューズなしに取り組むことができるでしょう! ![]()
(::pragma function <f:function kind="library" visibility="protected" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:transformToEMP2($emp as element(empl:Employee)?) as element(emp2:EMP2)? { for $emp1 in $emp return <emp2:EMP2> <EmpId>{fn:data($emp1/EmployeeID)}</EmpId> <FirstName>{fn:tokenize(fn:data($emp1/Name),' ')[1]}</FirstName> <LastName>{fn:tokenize(fn:data($emp1/Name),' ')[2]}</LastName> <MgrName>{fn:data(ens1:getByEmployeeID($emp1/ManagerID)/Name)}</MgrName> <Dept>{fn:data($emp1/DeptNo)}</Dept> </emp2:EMP2> };
XQuery「T」ヘルパー関数によって、XQSE の iterate 文を使用して、「E」部分、たとえば、ソースシステムから必要なデータを抽出することができます。同じ関数を使用して、「L」部分、たとえば、ロード作業をすることもできます。以下の XQSE で書かれたプロシージャは、getAll() 関数を使用して、従業員インスタンスをすべて、Employee データ サービスからコピーし、変形して、EMP2 DS に挿入します。また、移動中に処理したインスタンス数も保持し返します。
これは、EmployeeBackup.ds の 2 番目の操作で、copyAllToEMP2() をコピーします。
(::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:copyAllToEMP2() as xs:integer { declare $backupCnt as xs:integer := 0; declare $emp2 as element(emp2:EMP2)?; iterate $emp1 over ens1:getAll() { set $emp2 := tns:transformToEMP2($emp1); emp2:createEMP2($emp2); set $backupCnt := $backupCnt + 1; } return value ($backupCnt); };
Factoid : このプロシージャは、この比較的に単純な反復ループのため、データを実際に「合理化」します。これは書かれているように、すべてのデータを一回にで実現する必要はなく、1 つのデータを一回で抽出したり、変形したり、ロードしたりします。(記述子の「lightweight」によって、要求が正確に述べた場合、操作が正常に行われます。この場合には、そうします。)
EmployeeBackup.ds の 3 番目と最後の操作は、deleteAllEMP2() です。この関数は、XQSE の iterate 文を使用して、EMP2 DS のインスタンスをすべて削除します。
(::pragma function <f:function kind="library" visibility="protected" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:deleteAllEMP2() as xs:integer{ declare $deleteCnt as xs:integer := 0; iterate $emp2 over emp2:EMP2() { emp2:deleteEMP2($emp2); set $deleteCnt := $deleteCnt + 1; } return value ($deleteCnt); };
このプロシージャは、XQSE How-To プロジェクトのコピーを使用して、この例を試して見るように追加されています。試して!まず、テスト ビューを使用して、Employee.ds および EMP2.ds を確認します。これらに、データ別に何が含まれているかを確認します。Employee の getAll() 関数は、Employee の内容を表示し、EMP2 の EMP2() 関数は、EMP2 の内容を表示します。
最初に、EMP2 には、データが何もありません。copyAllToEMP2 を実行して見てください。 Voila!ALDSP 3.0, での、我々のモットーは 「満足を保証することとデータのバックアップを 2 倍にすること」 です。![]() EMP2 には、目的とおりに、すべての Employee データの変形されたコピーが含まれます。true を返すのは、良いです。deleteAllEMP2 を実行すると、EMP2 のデータがすべて削除されます。再度、copyAllToEMP2 を実行して見てください。これは、lightweight ETL の操作です。
EMP2 には、目的とおりに、すべての Employee データの変形されたコピーが含まれます。true を返すのは、良いです。deleteAllEMP2 を実行すると、EMP2 のデータがすべて削除されます。再度、copyAllToEMP2 を実行して見てください。これは、lightweight ETL の操作です。
ほとんど、そこに到着しました。最後のユース ケースでは、更新をカスタム化にするために XQSE の使用パターンを見ましょう。これは、どう行うかの例を見ましたが、このパターンは、詳細に注意する必要があります。XQSE では、try 文を使用して、例外をどのように処理するかを説明するために、このユース ケースを使用すれば、さらに興味深くなります。
このユース ケースでは、目的は、ReplicatedEmployee データ サービスを作成することです。Employeee データ サービスでは、このデータ サービスが「フロント」ですが、両方のデータ サービスへの変更 (作成、更新、削除) を EMP2 データ サービスにも通知します。
このユース ケースは、EmployeeBatch 例に使用したバッチ アプローチではなく、XQSE を使用して、データの複製をリアルタイムでどのように処理するかについて説明します。バッチと増分複製は、それぞれの機能があります。我々の目的は、それぞれがどのように機能するかを示すことです。XQSE を使用すると、独自のユース ケースに発生される問題を解決することができます。
ReplicatedEmployee データ サービスを開いて、そのデザイン ビューに移動すると、以下を見ることができます。
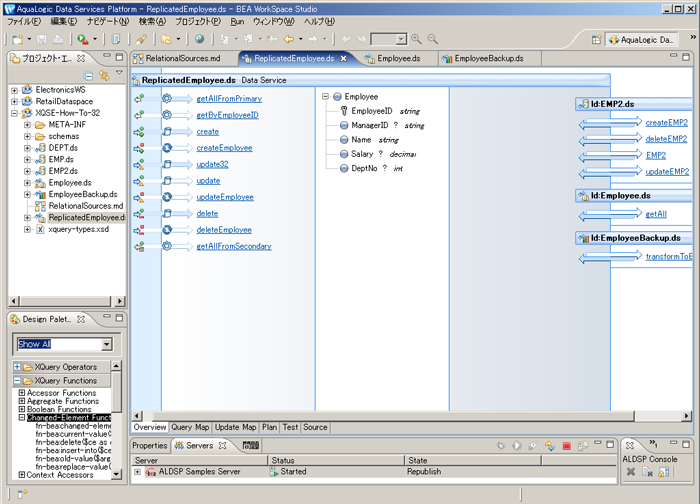
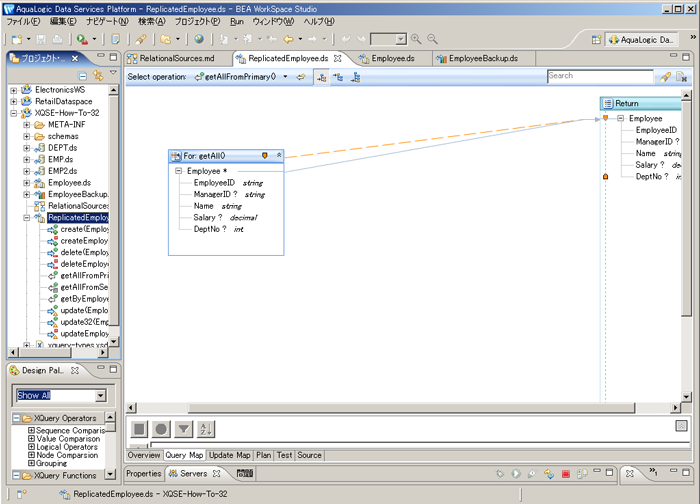
1 番目の getAllFromPrimary() 関数は、ReplicatedEmployee DS のプライマリ読み込み関数です。この関数の定義は非常に簡単です。この関数は、このデータ サービスが「フロント」として機能する Employee データ サービスの内容を受信します。この関数のクエリ マップ ビューでの定義は、世界中の最も簡単なグラフィカルなクエリです。
ReplicatedEmployee データ サービスには、2 つのその他の関数があります。1 つは、getByEmployeeID です。この関数は、プライマリ読み込み関数の単純なクエリで、パラメータとして従業員 ID を取ります。もう 1 つは、getAllFromSecondary です。この関数は、インクルードされたライブラリ関数であるから、XQSE How-To サンプル プロジェクトのコピー内のデータ サービス間に移動しなで EMP2 の内容を検査することができます。結果として起こるすべての 3 つの関数のソース コードは、以下のとおりです。参照してください。
(::pragma function <f:function kind="read" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getAllFromPrimary() as element(empl:Employee)* { for $Employee in emp1:getAll() return $Employee }; (::pragma function <f:function kind="read" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getByEmployeeID($id as xs:string?) as element(empl:Employee)? { for $Employee in tns:getAllFromPrimary() where $id eq $Employee/EmployeeID return $Employee }; (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare function tns:getAllFromSecondary() as element(emp2:EMP2)* { for $EMP2 in emp2:EMP2() return $EMP2 };
これらの関数に加えて、ReplicatedEmployee データ サービスには、6 つのプロシージャがあります。作成プロシージャ 2 つ、更新プロシージャ 2 つおよび削除プロシージャ 2 つ。これらの 3 つは、ALDSP によって、C/U/D プロシージャを持つ更新マップを求めて作成されました。これらの 3 つは、createEmployee()、updateEmployee()および deleteEmployee() です。それらのソース ビュー内の定義は、以下のとおりです。
(::pragma function <f:function kind="update" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:updateEmployee($arg as changed-element(empl:Employee)*) as empty() external; (::pragma function <f:function kind="create" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:createEmployee($arg as element(empl:Employee)*) as element(empl:ReplicatedEmployee_KEY)* external; (::pragma function <f:function kind="delete" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:deleteEmployee($arg as element(empl:Employee)*) as empty() external;
ReplicatedEmployee DS の更新マップ ビューを見ると、これらの 3 つのプロシージャの使用方法と実際に行っている機能を理解します。

このデータ サービスのプライマリ読み込み関数は、Employee データ サービスからの内容のみ読み込むため、システム提供の更新プロシージャは Employee データ サービスに対する変更のみ反映します。ALDSP は、これらの変更を EMP2 にも反映することが分かりません。これらの変更を EMP2 にも反映させるには、システムの更新機能をオーバーライドする必要があります。
これによって最後のユース ケースの中心ーXQSE プロシージャを完了することになります。続けて、6 つの更新プロシージャのプライマリ、非プライマリおよびパブリック、プライベートアノテーションに注意してください。前と同じ方法を使用します。たとえば、システム生成プロシージャをプライベートと非プライマリと見なします。XQSE を使用して、独自の更新プロシージャ (システム生成プロシージャを呼び出す) を書き、新規関数をパブリックとプライベート更新プロシージャとしてマークします。そうすることで、このデータ サービスのその他の利用者に関する独自の更新プロシージャが更新プロシージャになります。
必要な複製処理をどう行うことができますか。簡単です。以下のソース コードは、XQSE を使用して、複製の方法でユース ケースの作成方法を示します。
このプロシージャは、新しい Employee インスタンスに対して反復します。従業員ごとに、以前の変換関数を使用して、EMP2 において必要な形式で Employee インスタンスのコピーを作成します。その後、システム生成 createEmployee() プロシージャを呼び出し、新しい Employee インスタンスを作成します。次に EMP2 の createEMP2() プロシージャを呼び出したり、それに変換したコピーを渡したり、新しい EMP2 インスタンスも作成します。
ここで、try/catch を使用すると、各呼び出しは、XQSE try-block に存在するため、try/catch に失敗した場合、例外が catch-block に取得されます。catch-block ロジックは、新しい例外を送出し、呼び出し側に障害の場所 (プライマリまたはセカンダリ コピー) を示します。fn:concat() を使用する場合、問題の元の原因が失われないように注意します。
(::pragma function <f:function kind="create" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:create($newEmps as element(empl:Employee)*) as element(empl:ReplicatedEmployee_KEY)* { iterate $newEmp over $newEmps { declare $newEmp2 as element(emp2:EMP2)?:= bns:transformToEMP2($newEmp); try { tns:createEmployee($newEmp); } catch (* into $err, $msg) { fn:error(xs:QName("PRIMARY_CREATE_FAILURE"), fn:concat("Create failed on primary copy due to: ", $err, $msg)); }; try { emp2:createEMP2($newEmp2); } catch (* into $err, $msg) { fn:error(xs:QName("SECONDARY_CREATE_FAILURE"), fn:concat("Create failed on backup copy due to: ", $err, $msg)); }; } };
明確になりましたか。XQSE How-To プロジェクトのコピーを扱えるようにするため、テスト ビューでこのプロシージャを試して見てください。既に存在する従業員を作成して、なにが起こるかを見てください。さらに情報を扱えるには、さまざまなエラーシナリオが発生されるように基底の Employee データ サービスおよび EMP2 データ サービスを試して見てください。たとえば、1 つまたはその他のデータ サービスに 1 つのインスタンスを手動で作成し、ReplicatedEmployee の create を使用して、両方のデータ サービスではなく、いずれかのデータ サービスの主キーとの衝突が発生するようにします。プライマリおよびセカンダリの両方の create に失敗の例外が発生するかを見てください。
複製を完全に理解するには、deletes ならびに creates を複製する必要があります。以前に行った処理と逆の処理を行う必要があります。delete には、以下の XQSE プロシージャを使用します。まず、Employee インスタンスを取得し、それぞれに対して反復します。各インスタンスの EMP2 コピーを作成します。このデータ サービスに対して、deleteEmployee() と EMP2 DS に対してdeleteEMP2() を使用して両方の基底の DS を削除します。この場合には、同じ例外処理のパターンを使用します。
(::pragma function <f:function kind="delete" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:delete($oldEmps as element(empl:Employee)*) { iterate $oldEmp over $oldEmps { declare $oldEmp2 as element(emp2:EMP2)?:= bns:transformToEMP2($oldEmp); try { tns:deleteEmployee($oldEmp); } catch (* into $err, $msg) { fn:error(xs:QName("PRIMARY_DELETE_FAILURE"), fn:concat("Delete failed on primary copy due to: ", $err, $msg)); }; try { emp2:deleteEMP2($oldEmp2); } catch (* into $err, $msg) { fn:error(xs:QName("SECONDARY_DELETE_FAILURE"), fn:concat("Delete failed on backup copy due to: ", $err, $msg)); }; } };
また、基底のデータ サービスでも、プライマリおよび delete の両方の障害を発生させるようにすることができるかを試して見てください。
最後に、updates も複製する必要があります。updates (変更を持つインスタンス) を処理するのは難しいです。更新の時、独自の複製ユース ケースは、更新をどのように処理されるかについて、詳しく考える必要があります。
update の場合も、create/delete と同じパターンを使用します。主な相違点は、入力として、変更した Employee インスタンスのリストを取得します。変更された EMP2 インスタンスに対応するリストはありません。ALDSP 3.0 では、1 つを計算する方法はありません。ALDSP 3.0 では、データ サービスを非相称的に扱う必要があります。そうすると、システム生成 updateEmployee() プロシージャを使用して、Employee 更新を Employee データ サービスに反映することができます。該当する変更を EMP2 に反映するには、各インスタンスの古いバージョンを削除し、その必要な新しいバージョンを挿入します。
必要なバージョンを取得し、変形するには、fn-bea:old-value() および fn-bea:current-value() 関数を使用します。処理は以下に示します。
(::pragma function <f:function kind="update" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:update($changedEmps as changed-element(empl:Employee)*) { iterate $changedEmp over $changedEmps { try { tns:updateEmployee($changedEmp); } catch (* into $err, $msg) { fn:error(xs:QName("PRIMARY_UPDATE_FAILURE"), fn:concat("Update failed on primary copy due to: ", $err, $msg)); }; try { declare $oldEmp as element(empl:Employee)?:= fn-bea:old-value($changedEmp); declare $newEmp as element(empl:Employee)?:= fn-bea:current-value($changedEmp); declare $oldEmp2 as element(emp2:EMP2)?:= bns:transformToEMP2($oldEmp); declare $newEmp2 as element(emp2:EMP2)?:= bns:transformToEMP2($newEmp); emp2:deleteEMP2($oldEmp2); emp2:createEMP2($newEmp2); } catch (* into $err, $msg) { fn:error(xs:QName("SECONDARY_UPDATE_FAILURE"), fn:concat("Update failed on backup copy due to: ", $err, $msg)); }; }; };
また、発生した障害にフラグをたてるには、try/catch を使用します。テスト ビューを使用して、一部の ReplicatedEmployee インスタンスをアクセスしたり、編集したり、変更を保存します。 さらに、さまざまな種類の障害を含めて、基底のソースのデータと変更点の状態を試して見てください。給与額を 10% より大きくすると、何が起こるかを見てください。なぜ。
ALDSP 3.2 では、mutator 関数に加えて、複製済みの更新ユース ケースを扱うために別の方法があります。Mutators には、EMP2 の必要な変更点のリストを計算する方法があります。このことを行うには、update() 関数を書き直した結果取得した update32() を見てください。この関数は、update() と同じ様に、最初に、変更済みの各従業員の該当する新旧 EMP2 値を計算します。ただし、古く値を削除して、新しい値を挿入する代わりに、update32() は、各変更を適切に反映するために、新しい値と古い値間の差 (EMP2 スキーマに基づく) を分析します。その後、mutator 関数を使用して、変更要素に対しての各変更を反映することで、新旧の EMP2 の状態の相違点を考慮するための方法としてのみ変更されます。XQSE コードに示すように、 EMP2 の各要素が新規に追加されたのか、新規に削除されたのか、その値が変更されたのか、変更されていないのかを表していることに注意してください。このように EMP2 要素をすべて検討した後、EMP2 の更新ルーチンおよび結果として起こる変更済みの要素のインスタンスが呼び出されます。
(::pragma function <f:function kind="update" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:update32($changedEmps as changed-element(empl:Employee)*) { iterate $changedEmp over $changedEmps { try { tns:updateEmployee($changedEmp); } catch (* into $err, $msg) { fn:error(xs:QName("PRIMARY_UPDATE_FAILURE"), fn:concat("Update failed on primary copy due to: ", $err, $msg)); }; try { declare $oldEmp as element(empl:Employee)?:= fn-bea:old-value($changedEmp); declare $newEmp as element(empl:Employee)?:= fn-bea:current-value($changedEmp); declare $oldEmp2 as element(emp2:EMP2)?:= bns:transformToEMP2($oldEmp); declare $newEmp2 as element(emp2:EMP2)?:= bns:transformToEMP2($newEmp); declare $chgdEmp2 as changed-element(emp2:EMP2)?:= fn-bea:changed-element($oldEmp2); (: figure out what's changed and note ONLY those changes in the backup copy :) if (not($newEmp2/MgrName eq $oldEmp2/MgrName)) then { if (fn:empty($oldEmp2/MgrName)) then { set $chgdEmp2 := fn-bea:insert-into($chgdEmp2, ".", $newEmp2/MgrName); } else if (fn:empty($newEmp2/MgrName)) then { set $chgdEmp2 := fn-bea:delete($chgdEmp2, "MgrName"); } else { set $chgdEmp2 := fn-bea:replace-value($chgdEmp2, "MgrName", fn:data($newEmp2/MgrName)); }; }; if (not($newEmp2/FirstName eq $oldEmp2/FirstName)) then { if (fn:empty($oldEmp2/FirstName)) then { set $chgdEmp2 := fn-bea:insert-into($chgdEmp2, ".", $newEmp2/FirstName); } else if (fn:empty($newEmp2/FirstName)) then { set $chgdEmp2 := fn-bea:delete($chgdEmp2, "FirstName"); } else { set $chgdEmp2 := fn-bea:replace-value($chgdEmp2, "FirstName", $newEmp2/FirstName); }; }; if (not ($newEmp2/LastName eq $oldEmp2/LastName)) then { if (fn:empty($oldEmp2/LastName)) then { set $chgdEmp2 := fn-bea:insert-into($chgdEmp2, ".", $newEmp2/LastName); } else if (fn:empty($newEmp2/LastName)) then { set $chgdEmp2 := fn-bea:delete($chgdEmp2, "LastName"); } else { set $chgdEmp2 := fn-bea:replace-value($chgdEmp2, "LastName", $newEmp2/LastName); }; }; if (not($newEmp2/Dept eq $oldEmp2/Dept)) then { if (fn:empty($oldEmp2/Dept)) then { set $chgdEmp2 := fn-bea:insert-into($chgdEmp2, ".", $newEmp2/Dept); } else if (fn:empty($newEmp2/Dept)) then { set $chgdEmp2 := fn-bea:delete($chgdEmp2, "Dept"); } else { set $chgdEmp2 := fn-bea:replace-value($chgdEmp2, "Dept", $newEmp2/Dept); }; }; emp2:updateEMP2($chgdEmp2); } catch (* into $err, $msg) { fn:error(xs:QName("SECONDARY_UPDATE_FAILURE"), fn:concat("Update failed on backup copy due to: ", $err, $msg)); }; }; };
ここまで成功した場合、すべての資料に目を通して、提案されたすべての練習を試してみたことになります。おめでとうございます!「XQSE マスター」になりました。履歴書を開いて、「プログラミング言語」のリストに「XQSE」を追加してください。これは、他の誰の履歴書にも存在しません。
ALDSP 3.0 では、XQSE を使用して次のさまざまな種類のことを行うことができます。XQuery では実現不可能または非常に難しいとされる、読み込み関数を記述することができます。副作用の動作をカプセル化する XQSE にプロシージャを記述することできるようになります。つまり、クライアントに実行させたい事柄を、記述し、テストし、最適な時間に準備ができていることが保障されているデータサービス オペレーションを使用するだけで可能になるのです。
XQSE を使用することで、以前は行われなかった軽量 ETL タスクを、ほかのエンタープライズ ソフトウェア ツールや six-figure P.O を開始することなしに、処理することもできるようになります。
XQSE を使用して、システムの自動化された更新処理ロジックを独自の XQSE コードに置換または増強して、更新をカスタム化することができます。また、まだ想像もしない(二の足を踏んでいたと思われる ![]() )ようなことへの可能性も開けることは言うまでもありません。先に進んで、興味深いさまざまな XQSE を見てください。また、この言語はいかがかお知らせください。
)ようなことへの可能性も開けることは言うまでもありません。先に進んで、興味深いさまざまな XQSE を見てください。また、この言語はいかがかお知らせください。